简介
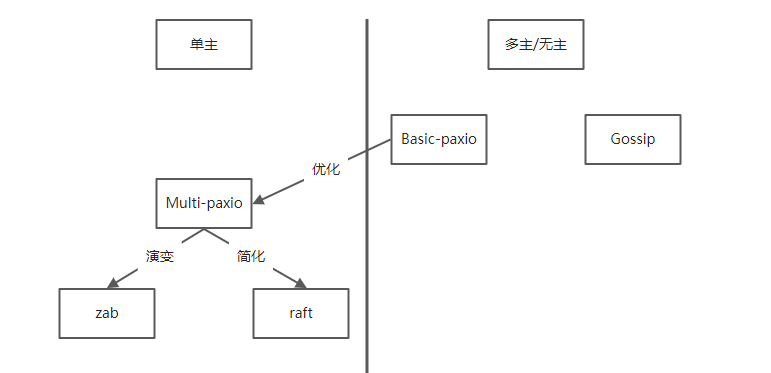
paxio协议更加偏向于分布式共识思想,而不是一种具体实现算法 Gossip、zab、raft则是实际实现的,细节会更加丰富 从是否有leader可以分为单主与无主
Basic-paxio
聚焦点:如何达成共识 在paxio协议中,每个节点都有提案权、投票权,当需要对一个事务形成共识时,要经历两阶段过程 一阶段:提案阶段(prepare)
- 提案节点向其余节点发送提案信息(id,i,1),代表当前的提案id和希望设置i=1的共识
- 其余节点在收到消息后,会做出两个承诺和一个回应
承诺:
- 承诺不再回应小于或等于提案id的提案(prepare)
- 承诺不接受小于提案id的提案(accept)
回应:
在自己的已提交提案中,找到最大的提案id对应的值并返回,若没有相应提案,则返回null
- 提案节点在收到过半数量的回应后,进入下一阶段
二阶段:确认阶段(accept)
- 提案节点向其余节点发出确认消息
- 其余节点根据自己的消息情况选择回应或不处理,回应规则为一阶段步骤2中的承诺2。
- 提案节点在收到超过半数的消息后,提交该提案并通知其余节点
- 其余节点收到通知消息后提交自己的提案
paxio的两个问题 一、活锁问题 在一阶段结束后,假设其他节点又收到了(x+1,i, 2)的prepare信息,此时其他节点
- 不再回应小于或等于x+1的提案
- 不再接受小于x+1的确认
而后再收到最初的提案节点的确认请求(x,i,1),由于x < x+1,故不再被其余节点接受,以上情况在极端情况下可能会一直循环发生,形成活锁。 二、性能问题 对于每个提案的成功接收,需要两阶段过程,即两阶段IO
Multi-paxio
为了解决以上问题,Multi-paxio诞生了,Multi-paxio通过选主来解决io和活锁的问题。 角色:提案节点、决策节点、学习节点 如何选主? Multi-paxio的选主过程为Basic-paxio,这里不再赘述。在选出leader节点后,其余节点为follower,主从之间通过心跳来进行判活。 如何复制数据? 在Multi-paxio中,每次提案都由leader来完成,leader收到客户端请求后
- 提案节点发送信息(1,id,i,1)给决策节点,表示当前任期是1,提案id为id,希望设置i=1
- 决策节点在收到信息后,判断与当前任期的情况,若任期相同,则返回同意,否则说明当前落后,与leader进行数据同步
- 提案节点在收到过半的票数后提交提案,广播给其余决策节点
- 其余决策节点在收到广播后提交提案
网络分区情况 假设现在有一个有s1,s2,s3,s4,s5组成的集群,当前s1为leader,此时网络分为了两部分,s1+s2和s3+s4+s5,此时s3这个集群发现无法与s1进行通信后,开始投票选举新的leader。假设选为了s3,此时s3继续正常进行工作。此时s1集群由于不满足大多数,无法在提交提案。当网络分区恢复后,s1,s2回滚自己未提交的提案,与s3同步数据 Multi-paxio能保证提案的顺序吗? 不能
Zab
专门为zookeeper设计的协议。在zab协议中,每个节点有4中状态
looking:寻找主节点状态 follow:跟随着 leader:领导者 observer:观察者
故障恢复阶段
- leader故障,follower在一段时间没有收到心跳后,将本身状态设为looking,并开始进行投票选举,将自身的任期+1而后发送(zxid,sid)给其他集群中的follower节点
zxid为long类型,高32位表示任期,低32位表示提案id,任期和提案id都是单调递增的 sid为一个类似myid的唯一标识
- 其他follower收到提议后,将自身状态设为looking,若已经是looking,则开始进行领导者pk。pk依据为:任期 > 提案id > sid,最终投出自己的票
- 每个looking节点根据自己的票选情况,来判断自身状态,若当选,则将自身状态改为leader,否则改为follow,并广播给其余follower
- 所有follower与新leader进行数据同步,follower将自身的最大事务id:fid发送给leader。leader会为每个follower开辟事务提交队列。当前队列最小的事务id:minid,当前队列最大的事务id:maxid
- 当minid < fid < maxId时
- 若fid在队列中能找到对应项,则说明follower落后leader,同步缺失数据到follower
- 若fid在队列中不能找到对应项,则说明有冲突数据,此时以leader数据为准,follower先回滚再同步
- 当fid < minid时,说明follower远远落后leader,同步leader的snapshot
- 当fid > maxid时,说明follower中有多余的提案,此时有两种情况
- follower单纯的领先leader,此时回滚到maxid即可
- follower与leader有冲突节点,此时要先回滚在同步
- 当minid < fid < maxId时
- 集群恢复正常,可继续对外提供服务
消息广播阶段
- leader接收到客户端请求,生成事务id,将信息和zxid广播给follower
- follower收到后,将消息中的任期与本身任期对比
- 任期一致,暂存
- 任期 < 本身任期,说明是上一任leader,不予处理
- 任期 > 本身任期,说明自身落后,开始与leader进行数据同步
- leader收到过半ask后,提交本地事务,并广播提交指令给follower
- follower在收到commit指令后,将本地暂存的zxid于指令中的zxid作比较,若一致则提交,不一致则与leader进行数据同步
ps:步骤中的加黑字体是从节点保持数据顺序性的关键
Raft
角色状态:leader、follower、候选人 Raft中的提案叫日志 如何选主? 当follower超时未收到leader的消息时
- follower自己成为候选人,将自己的任期+1,而后向所有人发送要参选的消息。
- 其余follower收到消息后,根据如下规则进行投票,当有并发情况时,遵循先到先得原则
- 自己的任期 < 消息中的任期
- 自己的最大日志id < 消息中的最大id,即follower不会投票给日志落后于自己的节点
- 候选人收到超过半数的票后则当选leader,而后向其余节点广播当选消息
- 其余follower与leader进行数据同步,leader发送自己的最新消息(rq,logId),任期和logid,follower将其与自己的日志进行比较
- 若未找到,则leader发送再前一个日志节点二元组(rq,logid)
- 若找到,则同步当前日志到最新日志的所有日志给follower
如何复制数据?
- leader将日志广播给follower节点
- follower将日志中的信息与自身信息作比较,若任期和日志id都满足要求,则恢复ack
- leader收到过半ack后恢复客户端
ps:leader不发送确认消息,follower如何提交呢 leader会将自己已提交的日志通过心跳发送给follower,每个follower收到心跳后提交自己的日志
Gossip
多主形式 每个节点都可以发起提案。而后广播给若干个其他节点,这里广播有两种方式 反熵 每次同步时节点之间数据全量同步 传谣 每次同步只发送增量更新数据