ACID
目的:Consistency——一致性 手段
- Atomic——原子性
- isolution——隔离性
- durability——持久性
实现
持久性:redolog + binlog 原子性:undolog 隔离性:mvcc + 锁 + undolog
持久性
一条更新语句的执行步骤
| server层执行器 | innodb引擎层 |
|---|---|
- 查询指定数据 | | | |
- 从buffer pool中查询数据 | | | 3.1 查到则直接返回数据页 3.2 查不到则从磁盘中寻找数据页返回 | |
- 更新对应数据 | | |
- 将数据写回磁盘 | | | |
- 将数据写到buffer pool | | |
- 记录redolog,标记为prepare状态 | |
- 记录binlog | | |
- 调用提交接口 | | | |
- 将redolog对应数据标记为commit状态 |
这里是如何保证crash-safe呢?我们需要关注数据库在以下几个节点发生crash的情况
- 步骤8之前,数据没有记录在日志文件中
- 步骤8-9之间,日志记录到了redolog,但没有记录到binlog
- 步骤9之后,日志记录到了日志文件中
情况1,日志文件中根本没有数据,该事务执行rollback 情况2,只记录到了redolog而没有记录到binlog,执行rollback 情况3,redolog和binlog都已经记录的该事务,将redolog对应数据标记为commit,继续提交事务 这里的redolog其实只是更新到了redolog pool内存中,具体何时刷新到redolog_file中,是根据checkpoint机制来的
checkpoint机制
既然redolog日志和数据都是先进内存再更新到磁盘,为什么要多这一步呢?redolog的好处在哪?
- redolog是顺序写,而数据文件是随机写,随机写速度慢
- redolog并不需要把整个数据页都更新,io少
原子性
一条更新语句会先记录undolog,在对数据进行更新。这样在事务最终进行回滚时,就会根据undolog来进行回滚。
隔离性
MVCC
事务隔离级别 读未提交——read uncommit(RU) 读已提交——read commit(RC) 可重复读——repeat read(RR) 串行 ——serial
| 事务1 | 事务2 |
|---|---|
| truncate user; | |
| start transaction | start transaction |
| insert into user values(1); | |
| // 一 | |
| select count(*) from user | |
| commit; | |
| // 二 | |
| select count(*) from user | |
| commit; | |
| // 三 | |
| select count(*) from user |
| RU | RC | RR | Serial | |
|---|---|---|---|---|
| sql一 | 1 | 0 | 0 | 报错 |
| sql二 | 1 | 1 | 0 | 报错 |
| sql三 | 1 | 1 | 1 | 1 |
RU模式能读到未提交的数据,成为脏读 RC模式下,在同一个事务中,两次读到的结果不一样,称为不可重复读 RR模式下,事务之内读到的数据和事务之外的数据不一样,称为幻读 那么模式是如何实现的呢?这里要介绍两个概念 快照读 select * from user 当前读 update user set id = 2 where id = 1; delete from user where id = 1; select * from user where id = 1 for update;
ReadView(快照读)机制如下
在RC模式下,每次读都会创建一个readview 在RR模式下,每个事务只会创建一个readview 举例:
Lock
锁的分类
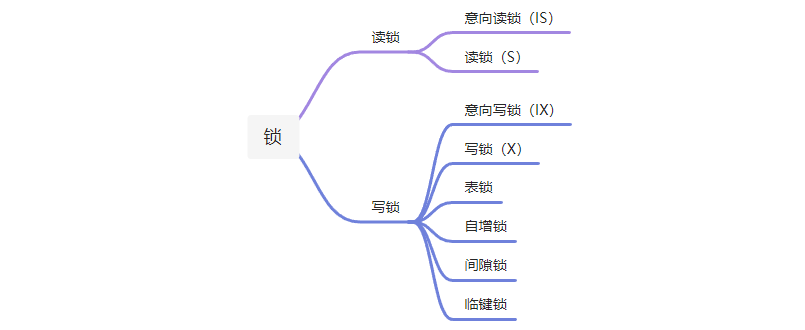
概念介绍
意向锁:为了简化加表锁的步骤,当需要加表锁时,需要遍历表中每行数据,数据都没锁才能加表锁,效率过慢,当加行锁的时候,首先在表上添加上意向锁 读锁:共享锁,行锁 写锁:互斥锁,行锁 自增锁:主键自增时加的锁 间隙锁:范围锁,又称GAP,前开后开 临键锁:范围锁,又称Next-key,前闭后开
读、写、意向锁的互斥关系如下
| 读锁 | 写锁 | 意向读锁 | 意向写锁 | |
|---|---|---|---|---|
| 读锁 | √ | X | √ | X |
| 写锁 | X | X | X | X |
| 意向读锁 | √ | X | √ | √ |
| 意向写锁 | X | X | √ | √ |
update student set age = 10 where id = 13 age的索引情况和数据库隔离级别,加锁的情况也不同
| 索引情况 | db隔离级别 | 加锁情况 |
|---|---|---|
| id为主键 | RC |
- 根据主键索引找到id=13的数据,在该索引上加写锁 | | id为唯一索引 | |
- 根据唯一索引找到id=13的数据,在该索引上加写锁
- 将这一行的主键索引上加写锁 | | id为普通索引 | |
- 根据索引找到id=13的所有数据,在该索引上加写锁
- 在锁住的数据中找到主键列,在主键列的唯一索引上加写锁 | | id不是索引 | |
- 对表中的每条数据都加锁 | | id为主键 | RR | 同上 | | id为唯一索引 | | 同上 | | id为普通索引 | |
- 根据索引找到id=13的所有数据,在该索引上加写锁
- 在加锁数据的前后间隙,加上GAP锁
- 在锁住的数据中找到主键列,在主键列的唯一索引上加写锁 | | id不是索引 | |
- 对表中的每条数据都加锁
- 对表中每条数据间隙加上GAP锁 |
复杂语句分析 table: user(id, age, userId, comment) index:idx_user_age(age, userId) delete from user where age > 1 and age < 20 and userid = 'hdc' and comment is not null;
参考文档
https://hoxis.github.io/mysql-zhuanlan-02-redolog-binlog.html https://www.cnblogs.com/wupeixuan/p/11734501.html https://zhuanlan.zhihu.com/p/52977862 https://km.sankuai.com/page/231603432