简介
redis支持的数据结构
- String——字符串
- Hash——哈希表
- list——双端队列
- set——无重复列表
- zset——无重复排序列表
其底层的数据结构实现
- SDS——动态字符串
- dict——字典
- quicklist——队列
- intset——int数组无重复列表
- ziplist——压缩队列
- skiplist——跳跃表
对应关系如下
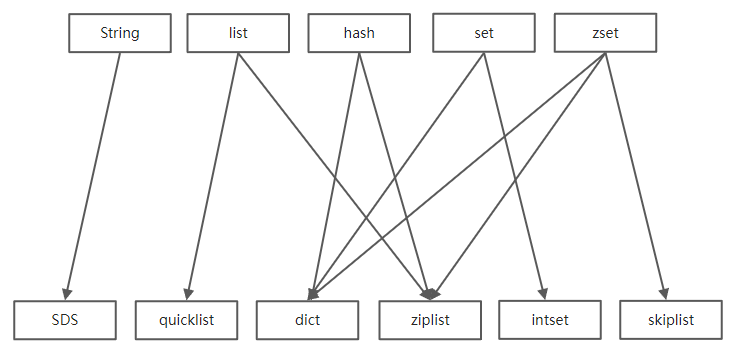
以上结果除了翻源码,redis使用时也有两个佐证
- 使用
object encoding key命令

- 查看redis.conf文件
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
2
3
4
5
6
7
8
9
底层结构详解
redis是由c语言进行开发的,c语言并没有提供丰富的库,所以redis将需要用到的数据结构都重写了一份
sds、skiplist
/* sds根据长度的不同分为sds5,sds8,sds16,sds32,sds64,使用字段中的flags进行标记
* 以下代码为sdshdr8的举例
* 其中sds5没有len和alloc字段
* 字符串内容放在buf[]中
*/
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
quicklist
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all listpacks */
unsigned long len; /* number of quicklistNodes */
signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *entry;
size_t sz; /* entry size in bytes */
unsigned int count : 16; /* count of items in listpack */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
quicklist是一个双向链表,每个quicklist由quicklistNode组成,每个quicklistNode由ziplist组成。
由于quicklist中更多的是对头尾数据的存取,中间的元素为了节约内存可以进行压缩,压缩算法为无损压缩算法LZF,压缩后的类型为quicklistLZF
quicklist的数据结构如下图

dict
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
众所周知redis是一个单线程模型的。如果redis中有过大的数据,在进行扩容时就会耗费一定的时间,这段时间服务不可用,为了解决这个问题,redis将rehash的过程分散,每次读、写请求时移动一个key。 触发节点 扩容:
- 当节点不在bgsave或bgrewriteaof并且factor > 1时,进行扩容
- 当节点在bgsave或bgrewriteaof且factor > 5时,进行扩容
缩容:当factor < 0.1时,进行缩容 触发rehash后步骤如下
- 将dict中的rehashidx标志改为rehash状态
- 创建扩容后大小的dictEntry
- redis在rehash时,每个对redis的请求操作都会附带进行一个key的移动
- 在所有key移动完毕后,将状态改为非rehash状态,并舍弃ht[1],以后的读写都是用新的dictEntry
在rehash的过程中 读:现在ht[0]中寻找,找到则直接返回,找不到则取ht[1]中找 写:直接在ht[1]上操作 这里有个问题需要注意 如果开启的rehash,之后没有请求打到redis,是不是redis的rehash就一直不会结束? 这里不是的,redis自己会其定时任务来完成rehash
intset
typedef struct intset {
// int的类型
uint32_t encoding;
// 类型长度
uint32_t length;
// 柔性数组
int8_t contents[];
} intset;
2
3
4
5
6
7
8
intset的长度为encoding * length encoding表示在柔型数组中最大项的类型,分为8,16,32,64 intset中的数据是有序的,读\写的时间复杂度都是O(logN),
ziplist
(源码没找到)
// ziplist
+---------+--------+-------+--------+--------+--------+--------+-------+
| zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
// ziplistEntry
+------------------+----------+--------+---------+
| pre_entry_length | encoding | length | content |
+------------------+----------+--------+---------+
2
3
4
5
6
7
8
9
ziplist释义
| zlbytes | zltail | zllen | zlend |
|---|---|---|---|
| ziplist的大小 | ziplist的尾部位置 | ziplist的长度 | 结束标志位 |
ziplistEntry
| pre_entry_length | encoding | length | content |
|---|---|---|---|
| 前一个节点的长度 | 数据类型 | 长度 | 内容 |
读:各个节点无序,O(n) 新增:有zltail记录尾部位置,O(1) 更新:要找到对应节点才能更新,O(n)